Every now and then I stumble upon a brilliant post on Internet, I share some of those links on my Diigo profile but the format is very succinct. I decided to start a new experiment and instead write full blog posts about those links. The first reason is quite selfish as I would like to keep a record of what I thought was interesting and why, I also hope to empower the reader so that she can decide if she wants to read the full post as some of them are lengthy.
I’m considering limiting each of those post to up to three links as to not require too much time from the reader.
This is inspired by the excellent work that Chris Alcock and Michael Wolfenden are doing with respectively The Morning Brew and The Wolf Report. Don’t be surprised if I end up stealing borrowing some links from them.
Without further ado let me get started with the first links.
How To Be a Programmer: A Short, Comprehensive, and Personal Summary
Link: https://www.doc.ic.ac.uk/~susan/475/HowToBeAProgrammer.pdf
This is a 40 pages long PDF but contains some invaluable lessons especially if you’ve been in the field for only a few years.
A classic mistake is to use a hash table as a cache and forget to remove the references in the hash table. Since the reference remains, the referent is uncollectable but useless. This is called a memory leak.
This is a mistake I’ve seen across almost all companies I’ve consulted for. I never managed to understand why dev teams adopted this anti-pattern as it has only drawbacks and is not simpler to write than a barebone caching system.
In the .NET word it’s often implemented via a static private Dictionary. Developers tend to use objects as key without understanding the requirements around equality but the main issue is that there is rarely code to remove keys which then requires an app pool restart (in a web app) in order to get rid of the stale key! This is compounded by the fact that sessions are often stored in process too and will be wiped out by an app pool restart.
- Caching is hard, only introduce caching if you need to (based on performance measurements and performance targets)
- Use the
System.Runtime.Cachingnamespace for in process caching - Cache data for the smallest amount of time you can get away with
- Have an API allowing you to interact with your caching system
- Consider using a distributed caching system (
Redisis great for this workload) - When using a distributed caching system, consider using a short lived in process cache
Never, ever, rest any hopes on vapor. Vapor is any alleged software that has been promised but is not yet available.
This situation happened in one of my previous engagement. The feature we were developing was tightly integrated with a product being built by a startup. Their CEO flew down to our office, we listed the API endpoints we required and development started straight away. We even had a support engineer assigned to us!
Two things started to happen:
- Already working features would break suddenly. After getting some support it would turn out that they pushed a new release that broke the feature. They would then deploy a patch which would break another feature!
- The core feature of this system was to poll third party services for created or modified entities. During our testing we noticed that entities were being missed frequently and we had to trigger the system manually for anything to happen. We raised those concerns and the startup promised to improve the reliability.
We were developing at a faster pace and started to mock more and more dependencies. The release date was approaching and we had no confidence the integration would work. The product we were working on had long release cycles and was deployed by our customers on their own infrastructure, a failure would have been catastrophic. It was finally decided to test the reliability of our provider, we also included one of their competitor. After a few days of collecting data the verdict came in and things weren’t looking good, even though the competitor captured 100% of the entities we created our provider missed almost 30% of them!
The CTO decided to scrap the integration on the spot and we ended up throwing away half of the code base.
What we did right was to investigate the unknowns early on in the project. Instead of building our infrastructure we developed a small proof of concept and were able to get a contrived end-to-end execution. The lesson that I learned is that you should define a SLA for your provider from day one and measure it.
How to Write a Git Commit Message
Link: https://chris.beams.io/posts/git-commit/
This is an amazing post, I’ve started to apply those rules a few months ago and my commit messages are so much better now.
Use the body to explain what and why vs. how
Giving context in the body is critical as often when fixing a bug I can see how it has been introduced but I have no idea why the change was made - even after reading the story associated with it! Please spend a few minutes explaining why and how a change was made, in 6 months or one year someone will be grateful. This someone might even be you!
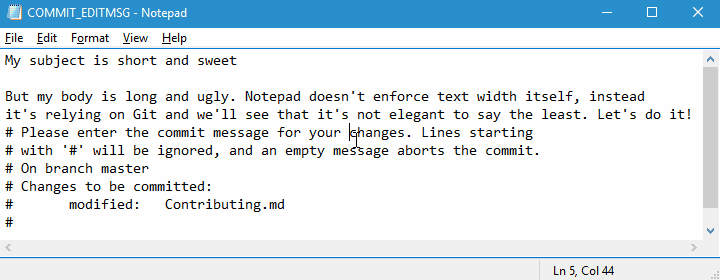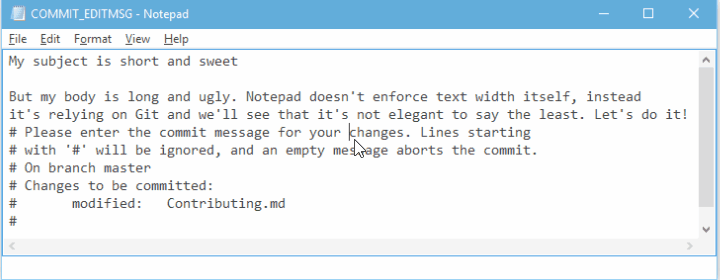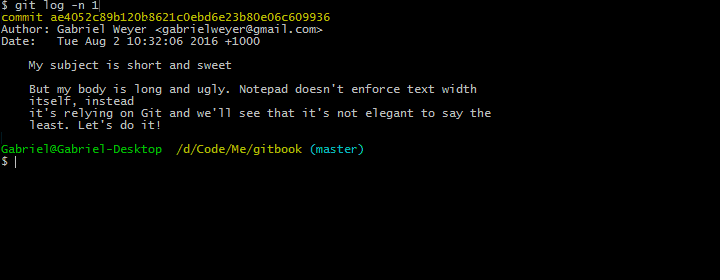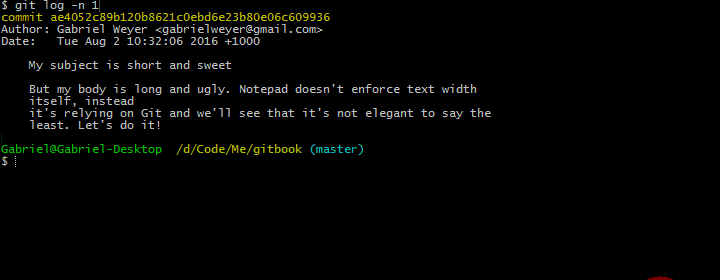
Wrap the body at 72 characters
I used to write my commit messages inline with the -m argument. After reading this rule I realized I needed an editor. I started to use Notepad++ by configuring Git this way:
git config --global core.editor "'C:\Program Files (x86)\Notepad++\notepad++.exe' -multiInst -notabbar -nosession -noPlugin"Notepad++ accepts command line switches but there is no switch to set the text width. Git has a setting enforcing the text width but it does not work with Notepad++. The good news is that Git can also use notepad and the text width will be enforced:
git config --global core.editor notepad
git config --global format.commitMessageColumns 72But the text will be wrapped after you save your commit message leading to a less than desirable result:
A better solution is to use vim instead:
git config --global core.editor vim
git config --global --unset format.commitMessageColumns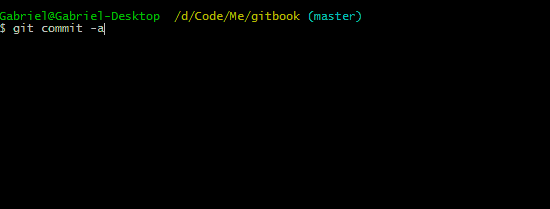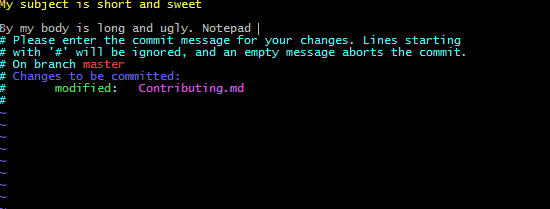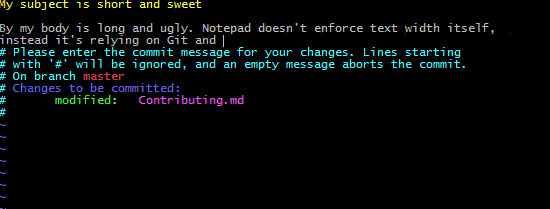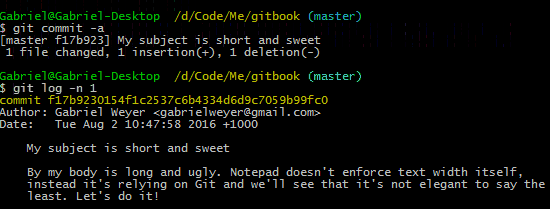
I did not hit Enter while typing the body of this commit message, instead vim wrapped it for me automatically. If you want to learn more about configuring Git on Windows I wrote a tutorial to get you started.